Running LLMs Locally in 2025 — The Best Options, Tools & Comparison Chart
AI & CYBERSECURITY
Zaheer Ikbal
10/26/2025


🧠 Running LLMs Locally in 2025 — The Best Options, Tools & Comparison Chart
Last updated: October 23, 2025
Reading time: ~7 minutes
Author: Zaheer Ikbal
🚀 Why Everyone’s Talking About Local LLMs
Big AI models no longer need big clouds.
In 2025, running large language models (LLMs) locally is not just possible — it’s practical.
Whether you want:
⚡ Instant, zero-latency replies
🔒 Private, offline inference
💸 No pay-per-token costs
🧩 Custom AI apps that don’t depend on APIs
…local LLMs deliver.
Thanks to smart quantization, optimized runtimes, and lightweight model formats, you can now run chatbots, copilots, or research assistants entirely offline — even on consumer laptops.
🧩 The Top Ways to Run LLMs Locally (as of 2025)
Let’s explore the most popular and effective local LLM options — from simple desktop apps to enterprise-grade GPU stacks.
🧱 1. llama.cpp / GGUF / GGML
💡 What it is:
A lightweight, C/C++-based runtime that lets you run models like Llama 2, Mistral, and Gemma efficiently on CPUs (and some GPUs).
✨ Why it rocks:
Works entirely offline
Super small footprint
Runs even on laptops & Raspberry Pi
Supports 4-bit to 8-bit quantized models
🧠 Perfect for:
Tinkerers, developers, and privacy enthusiasts who want full control.
⚙️ Pro Tip: Try Llama 3 8B Q4_K_M with llama.cpp — it’s smooth even on 16GB RAM machines!
💬 2. GPT4All, LM Studio, or Ollama (Desktop Apps)
💡 What they are:
All-in-one local AI apps that handle downloads, model management, and chatting — no code required.
✨ Why people love them:
Clean, chat-style interface
Works on Windows, macOS, and Linux
Automatic updates and plugins
RAG (Retrieval-Augmented Generation) built in
🧠 Perfect for:
Casual users, creators, or anyone who wants an AI companion running offline.
🖥️ Example: LM Studio lets you pick models like Mistral, Phi-3, or Llama 3 — just one click away.
🧬 3. Hugging Face Transformers + ONNX Runtime
💡 What it is:
The go-to Python framework for training, fine-tuning, and deploying open models.
✨ Why it rocks:
Huge model library
Supports GPUs, CPUs, and even edge devices
Converts to ONNX for faster inference
Perfect for integrating into your app or research pipeline
🧠 Perfect for:
Developers who love to experiment, train, and deploy custom models.
🔧 Pro Tip: Convert your model to ONNX — you’ll see up to 2–3× speedup on most GPUs.
⚙️ 4. NVIDIA TensorRT-LLM / TensorRT
💡 What it is:
NVIDIA’s performance-optimized inference stack for running huge models at lightning speed.
✨ Why it rocks:
Industry-leading GPU performance
FP8/INT4 quantization support
Speculative decoding & fused kernels
Production-ready deployment
🧠 Perfect for:
Teams or enthusiasts running RTX / A100 / H100 GPUs.
💥 Use case: TensorRT-LLM is what powers real-time assistants and high-load enterprise APIs.
🧮 5. Quantization Pipelines (GPTQ, AWQ, TinyChat)
💡 What it is:
Model compression tech that shrinks big models (like 70B) down to fit in local GPUs or even RAM.
✨ Why it rocks:
Makes massive models usable
Reduces VRAM by up to 75%
Little to no performance drop (if tuned right)
🧠 Perfect for:
Developers squeezing large models into smaller GPUs.
📉 Example: A 70B model at 4-bit can run on a 24GB GPU — previously impossible!
🧠 6. vLLM and Triton (Server-Grade Runtimes)
💡 What it is:
Optimized backends for large-scale serving — perfect for API or multi-user setups.
✨ Why it rocks:
Smart batching & memory optimization
Multi-GPU scaling
Super low latency
🧠 Perfect for:
Startups or enterprises building AI chat or API services.
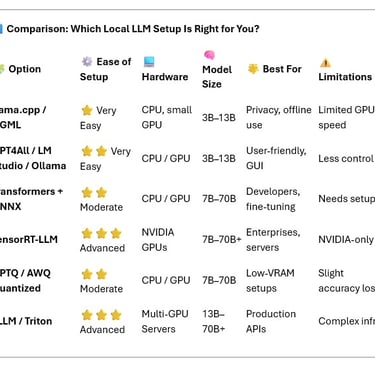
📊 Comparison: Which Local LLM Setup Is Right for You?
💡 Quick Recommendations
Use Case Best Pick Why 💻 Laptop chatbot llama.cpp / GPT4All Fast, easy, private 🧪 Fine-tuning Transformers + ONNX Maximum flexibility 🚀 High-performance servers TensorRT-LLM / vLLM Enterprise-level power 🧠 Low VRAM / small GPU GPTQ / AWQ Big models, small footprint
🔍 Key Terms in 10 Seconds
Quantization: Compressing weights (e.g., 16-bit → 4-bit) to save memory.
GGUF / GGML: Compact file formats for CPU/GPU inference.
Speculative Decoding: Predicts multiple tokens at once for faster generation.
RAG: Combines retrieval + generation for up-to-date responses.
⚠️ A Few Things to Keep in Mind
📜 Licenses vary — check usage rights for each model.
⚖️ Accuracy trade-offs — 4-bit quantization might slightly reduce precision.
💻 Hardware compatibility — not all tools support AMD or Apple GPUs yet.
🎯 Final Thoughts: The Future Is Local
Running LLMs locally is now practical, private, and powerful.
You don’t need a data center — just curiosity and a bit of setup.
For quick use, grab GPT4All or LM Studio.
For control and privacy, use llama.cpp.
For scale and performance, embrace TensorRT-LLM or vLLM.
🌍 2025 marks the year AI truly comes home.
Your laptop can now do what cloud servers did just two years ago.
📚 Further Reading